Introducción a Estructuras de Datos

El uso de estructuras de datos permite a las aplicaciones almacenar y procesar información de forma eficiente por este motivo es necesario revisar sus principales características.
Introducción
Cada aplicación necesita almacenar información de forma temporal o permanente, por ejemplo los datos de una persona, las medidas tomadas a una máquina, el detalle de ventas realizadas en un almacén, etc. Para esto los lenguajes de programación han previsto de contenedores de datos que permiten almacenar la información y procesarla de acuerdo a algún criterio. Estos contenedores se denominan estructuras de datos y se pueden clasificar en primitivas y complejas:
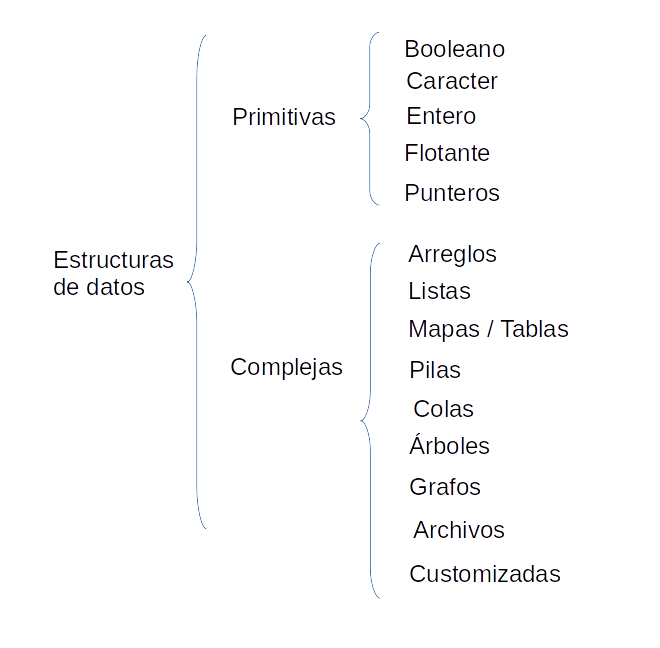 Imagen 1: Estructura de Datos
Imagen 1: Estructura de Datos
En este documento nos vamos a centrar en las estructuras complejas.
Arreglos
Un arrreglo es un contenedor de tamaño predefinido n, cuyos elementos se encuentran en espacios de memoria contigua y sus índices se encuentran entre los rangos 0 y n-1, su usos principalmente son :
- Almacenamiento temporal
- Como buffers de rutinas IO
- Envío de datos como argumentos en parámetros de métodos
- Retorno de datos en métodos
- Acceso randómico
Por ejemplo un arreglo de 4 elementos enteros cuyos valores son: 9, 5, -2, 7 puede ser representado de la siguiente manera:
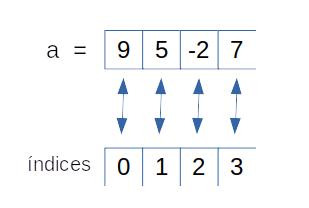 Imagen 2: Arreglo
Imagen 2: Arreglo
Cada elemento es accedido mediante su índice el cual inicia en 0, por ejemplo el último valor (7) puede ser accedido por el índice 3 así: a[3]=7
La definición de un arreglo es muy similar entre los lenguajes de programación, por ejemplo:
Golang:
a := [4]int{9,5,-2,7}
Java:
int[] a = {9,5,-2,7};
Los arreglos pueden tener varias dimensiones sin embargo no es recomendable el uso de más de tres dimensiones ya que pueden dificultar la lectura de un programa y generar errores. Un arreglo de dos dimensiones puede ser definido de la siguiente manera:
Golang:
b := [3][3]int { {5,3,7},{9,7,8},{0,-3,-3} }
Java:
int [][] b = { {5,3,7},{9,7,8},{0,-3,-3} };
Cada lenguaje provee varias alternativas para declarar arreglos sin embargo es necesario siempre definir el tamaño máximo del mismo n.
Golang
// Se define el arreglo mediante su tamaño n
var c [n]int
// Es posible definir los valores asignados a cada índice
c := [n]int{index i:value, index j:value}
Java
// Se define el arreglo mediante su tamaño n
int[] c = new int[n];
// El arreglo se define mediante los elementos asignados
int[] c = {value 1, value n};
// Se define e inicializa el arreglo mediante sus valores
int[] c = new int[]{value 1, value n};
Operaciones básicas
En un arreglo podemos encontrar las siguientes operaciones:
- Obtener (
get).- obtener el valor de un elemento en un índice - Tamaño (
size).- obtener el tamaño de un arreglo
Problemas más evidentes
Los principales inconvenientes con el uso de arreglos son:
- El tamaño de un arreglo es definido en su creación y no puede ser modificado.
- En Golang por defecto al pasar un arreglo a una función como parámetro se pasa la copia del arreglo, lo que puede significar lentitud si el arreglo es grande.
Para solventar estos problemas los lenguajes de programación han provisto de ciertas estructuras que permiten modificar su tamaño de forma dinámica como por ejemplo: Slices, Maps en caso de Golang o ArrayList, Vector en caso de Java entre otras.
Implementaciones
Golang / Slices
Sus características principales son:
- Es una estructura que permite incrementar o reducir su tamaño dinámicamente.
- Son implementados usando arreglos internamente.
- Pasados por referencia a funciones lo cual significa que no existe la necesidad de realizar una copia de todo el arreglo ya que se envía únicamente la dirección del mismo.
- No es sincronizado.
Un Slice puede ser declarado de la siguiente forma:
// El slice se define mediante los elementos asignados
c := []int{value 1, value n}
// El compilador identifica la longitud del arreglo basado en sus elementos
c := [...]int{value 1, value n}
// La función make permite la creación de un slice vacío con la longitud definida por n
c := make([]int , n)
Sus propiedades principales son: capacidad (capacity) y longitud (length). La longitud de un slice es la misma que la longitud de un arreglo y puede ser encontrada usando la función len(). La capacidad puede ser obtenida mediante la función cap() considerando que Go automáticamente duplica la longitud actual cada vez que se queda sin espacio para almacenar nuevos elementos, esto puede representar un inconveniente si se trata de un slice grande ya que puede tomar más memoria de lo esperado.
Java / ArrayList
En el caso de Java es posible generar arreglos dinámicos mediante la clase ArrayList que es una implementación de la interfaz List, sus principales características son:
- Es una estructura que permite incrementar o reducir su tamaño dinámicamente.
- Internamente usa un Array para almacenar sus elementos lo cuál permite devolver sus elementos por su índice.
- Permite valores duplicados y nulos.
- Mantiene el orden de inserción de sus elementos.
- No es sincronizado.
Un ArrayList puede ser declarado de la siguiente forma:
// Se define una lista de Strings de tamaño dinámico
List<String> c = new ArrayList<String>();
La longitud de un ArrayList puede ser obtenida mediante el método size() mientras su capacidad aumenta automáticamente iniciando en 10.
Listas enlazadas y doblemente enlazadas
En el caso de listas la diferencia más evidente es que sus elementos no se encuentran en espacios contiguos de memoria sin embargo cada elemento (al que se conoce como nodo) conoce la ubicación de su próximo valor, una de las ventajas principales de las listas sobre los arreglos es que las listas permiten cambiar su tamaño de forma dinámica permitiendo aumentar o disminuir su tamaño de acuerdo a su necesidad.
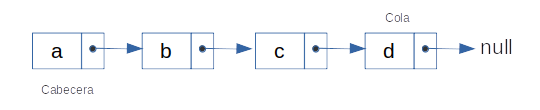 Imagen 3: Listas
Imagen 3: Listas
Cada nodo usa al menos dos espacios de memoria, uno para almacenar el dato actual y otro para almacenar un puntero al próximo elemento, de esta forma creando una secuencia de elementos que generan la lista. El primer nodo de la lista se conoce como cabecera (head) mientras el último nodo es denominado cola (tail).
El uso de listas enlazadas tiene grandes ventajas: son fáciles de entender y implementar, son lo suficientemente genéricas para ser usadas con estructuras más complejas y el proceso de búsqueda en ellas es rápido sin embargo una vez alcanzado un nodo no es posible alcanzar directamente el nodo anterior, para solucionar esto es posibles utilizar una implementación denominada Listas Doblemente Enlazadas las cuales permiten solucionar este inconveniente.
 Imagen 4: Listas Doblemente Enlazadas
Imagen 4: Listas Doblemente Enlazadas
Implementaciones
Golang
La implementación de una lista enlazada requiere la creación de una estructura que represente a un nodo, esta estructura deberá contener un valor y un puntero al siguiente elemento:
type Node struct {
Value int
Next *Node
}
A partir de esta estructura se podrán definir operaciones como
- agregarNodo (
addNode) - buscarNodo (
searchNode) - eleminiarNodo (
deleteNode) - atravesar (
traverse) - tamaño (
size).
Por ejemplo agregar nodo se puede definir de la siguiente forma:
func addNode(t *Node, v int) int {
if root == nil {
t = &Node{v , nil}
root = t
return 0
}
if v == t.Value {
fmt.Printf("El nodo ya existe: %d", v)
return -1
}
if t.Next == nil {
t.Next = &Node{v, nil}
return -2
}
return addNode(t.Next, v)
}
Golang provee una implementación para estructuras de tipo Listas Doblemente Enlazadas, esta implementación puede ser encontrada en el paquete “list”, un ejemplo de implementación es:
package main
import (
"container/list"
"fmt"
)
func main() {
// Crea una lista y agrega números a ella
l := list.New()
e4 := l.PushBack(4)
e1 := l.PushFront(1)
l.InsertBefore(3, e4)
l.InsertAfter(2, e1)
// Itera a través de la lista y imprime sus contendos
for e := l.Front(); e != nil; e = e.Next() {
fmt.Println(e.Value)
}
}
Java
La implementación de listas en Java es similar a la realizada en Golang, en caso de necesitar realizar una implementación propia podemos generar algo similar a lo siguiente:
class Node {
int value;
Node next;
}
En el caso del método agregarNodo(addNode) la implementación puede ser similar a la siguiente:
public int void addNode(Node t, int v) {
if root == null {
t = new Node( v , null );
root = t;
return 0;
}
if v == t.value {
System.out.Printf("El nodo ya existe: %d", v)
return -1
}
if t.next == null {
t.next = new Node(v, null);
return -2
}
return addNode(t.next,v)
}
En el caso de Java las implementaciones de listas son: AbstractList, AbstractSequentialList, ArrayList, AttributeList, CopyOnWriteArrayList, LinkedList, RoleList, RoleUnresolvedList, Stack, Vector, siendo LinkedList una implementación de tipo Lista doblemente enlazada.
Un ejemplo de uso de la clase LinkedList es:
import java.util.*;
public class EjemploLinkedList
{
public static void main(String args[])
{
LinkedList<String> users = new LinkedList<String>();
users.add("Mercedes");
users.add("Patricio");
users.addLast("Ximena");
users.addFirst("Alejandro");
users.add(1, "Edison");
System.out.println("Usuarios : " + users);
}
}
// Salida: Usuarios : [Alejandro, Edison, Mercedes, Patricio, Ximena]
Map / HashTables
Mapas y HashTables son estructuras equivalentes de tipo llave:valor siendo su principal característica el uso de un identificador (llave o key) el cuál tendrá asociado un valor con el condicionante que esta llave debe ser única y diferenciada del resto de llaves.
 Imagen 5: Map
Imagen 5: Map
El rendimiento de esta estructura depende de los siguientes factores:
- Función Hash
- Tamaño del HashTable
- Método de manejo de colisiones
Implementaciones
Golang / Map
Go no excluye ningún tipo de dato para ser usado como key siendo el único condicionante que los valores de key puedan ser diferenciados unos de otros. Su definición debe seguir este formato:
<nombre_variable> := make(map[key]tipo_valor)
//Ejemplo:
estudiantes := make(map[string]string)
estudiantes[1] = "Carla Flores"
estudiantes[2] = "Marco Salazar"
estudiantes[3] = "José Navas"
Esta estructura es más rápida y versátil que los arreglos y slices siendo muy conveniente su uso donde amerite una estructura de tipo llave/valor.
Java / Map
En Java, Map es una interfaz de tipo llave, valor (K,V) que a su vez es implementada por varias clases como: HashMap, HashTable, LinkedHashMap, TreeMap entre otras. En el caso particular de HashMap se permite el uso de valores nulos así como llaves nulas, esta clase es equivalente a Hashtable excepto en que no es sincronizada. Es importante indicar que no se garantiza que el orden de sus elementos permanezca constante a través del tiempo, se debe notar que los objetos usados como keys en un Hashtable deben implementar el método hashCode y equals.
// Se define un mapa cuyas llaves serán de tipo String y sus
// valores de tipo String
Map<String,String> map = new HashMap<String,String>();
// La definición de un hashTable es similar a la de un hashMap
// con la diferencia en que un hashTable es sincronizado lo cual
// significa que no es necesaria una implementación de tipo thread-safe.
Map<String,String> table = new Hashtable<String,String>();
Pilas
La característica principal de una pila o stack es que sus elementos utilizan para su procesamiento la técnica conocida como LIFO (Último en Entrar Primero en Salir), lo que significa que el elemento que es almacenado al final será el primer elemento en ser obtenido por la pila.
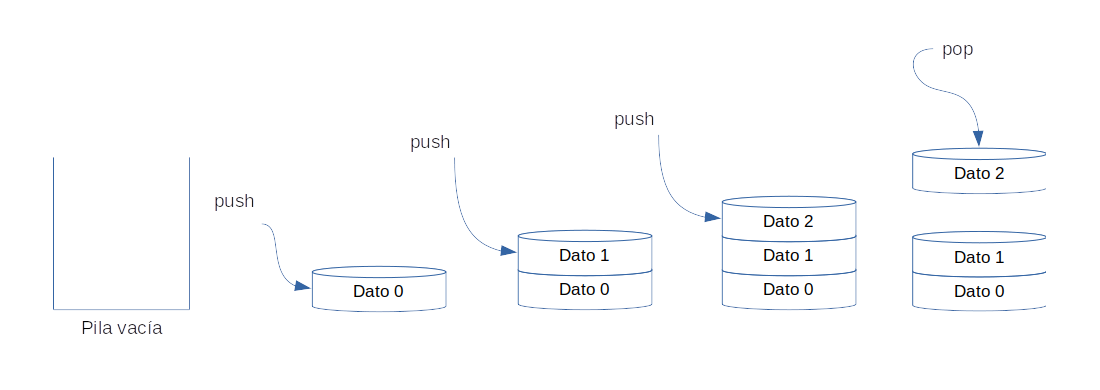 Imagen 6: Pila
Imagen 6: Pila
Operaciones básicas
Las operaciones básicas realizadas sobre pilas son:
Push: inserta un elemento en la cabecera de la pilaPop: obtiene el primer elemento de la pila removiendolo de la misma (LIFO)isEmpty: retorna verdadero si la pila se encuentra vacíaTop: retorna el primer elemento de la pila sin removerlo
Implementaciones
Golang
La implementación de una pila en Golang es similar a la implementación de una cola con la diferencia en que las pilas usan el método de almacenamiento LIFO (Último en Entrar Primero en Salir).
Una implementación posible de los métodos de una pila puede ser:
func Push(v int) bool {
if stack == nil {
stack = &Node(v,nil)
size = 1
return true
}
temp := &Node(v,nil)
temp.Next = stack
stack = temp
size++
return true
}
func Pop(t *Node) (int, bool) {
if size==0 {
return 0,false
}
if size==1 {
size = 0
stack = nil
return t.Value, true
}
stack = stack.Next
size--
return t.Value,true
}
func traverse(t *Node) {
if size == 0 {
fmt.Println("Empty Stack!")
return
}
for t != nil {
fmt.Printf("%d -> ", t.Value)
t = t.Next
}
fmt.Println()
}
Java
La implementación de pilas en java puede ser realizado de la siguiente forma:
public boolean push(int v) {
if( stack==null ){
stack = new Node(v,null);
size = 1;
return true;
}
temp = new Node(v,null);
temp.Next = stack;
stack = temp;
size++;
return true;
}
public int pop(Node t) {
if( size==0 ){
return 0;
}
if( size==1 ){
size = 0;
stack = nil;
return t.Value;
}
stack = stack.Next;
size--;
return t.Value;
}
public void traverse(Node t) {
if( size == 0 ) {
System.out.println("Empty Stack!");
return;
}
while( t != null ) {
System.out.println("%d -> " + t.Value);
t = t.Next;
}
}
Para el caso de pilas Java provee las implementación Stack que contiene los métodos necesarios para el proceso en forma LIFO.
Colas
Las colas siguen el mecanismo FIFO (First In First Out) para almacenar y obtener sus valores, esto significa que los primeros valores en ser insertados en una cola serán los primeros elementos en ser devueltos.
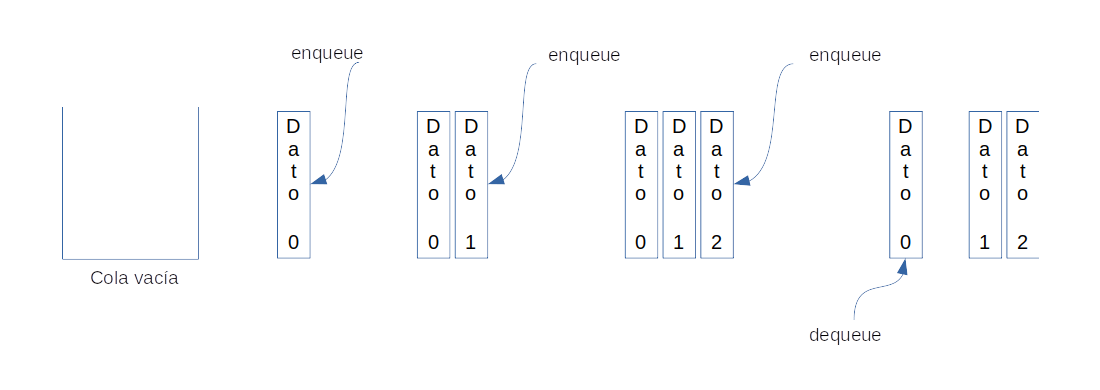 Imagen 7: Colas
Imagen 7: Colas
Operaciones básicas
Las operaciones básicas realizadas sobre colas son:
Enqueue: inserta un elemento al final de la colaDequeue: remueve un elemento desde el inicio de la cola (FIFO)isEmpty: retorna verdadero si la cola se encuentra vacíaTop: retorna el primer elemento de la cola sin removerlo
Implementaciones
Golang
La implementación de una cola en Golang necesita la definición de una estructura de tipo nodo y los métodos push y pop principalmente.
type Node struct {
value int
next *Node
}
func Push(t *Node, v int) bool {
if queue==nil {
queue = &Node(v, nil)
size++
return true
}
t = &Node{v,nil}
t.Next = queue
queue = t
size++
return true
}
func Pop(t *Node) (int, bool) {
if size==0 {
return 0, false
}
if size==1 {
queue = nil
size--
return t.Value, true
}
temp := t
for (t.Next) != nil {
temp = t
t = t.Next
}
v := (temp.Next).Value
temp.Next = nil
size--
return v, true
}
De las estructuras existentes en Golang se puede destacar que la implementación “container/list” pueden solventar el uso de colas.
Java
La implementación del algoritmo anterior (colas) puede ser realizado de la siguiente forma:
class Node {
int value;
Node next;
}
public boolean push(Node t, int v) {
if( queue==null ){
queue = new Node(v, null);
size++;
return true;
}
t = new Node(v,nil);
t.Next = queue;
queue = t;
size++;
return true;
}
public int pop(Node t) {
if( size==0 ){
return 0;
}
if( size==1 ){
queue = nil;
size--;
return t.Value;
}
temp = t;
while( t.Next ) {
temp = t;
t = t.Next;
}
int v = (temp.Next).Value;
temp.Next = null;
size--;
return v;
}
Java provee implemtaciones de colas a través de la clases que implementan la interfaz Queue tales como:
AbstractQueueArrayBlockingQueueArrayDequeConcurrentLinkedDequeConcurrentLinkedQueueDelayQueueLinkedBlockingDequeLinkedBlockingQueueLinkedListLinkedTransferQueuePriorityBlockingQueuePriorityQueueSynchronousQueue
Los cuales proveen los métodos necesarios para agregar y obtener nodos a una cola.
Árboles
Un árbol es una estructura jerárquica que consiste en la unión de vértices (nodos), usados como almacenamiento en algoritmos complejos en varios campos como índices para almacenamiento en bases de datos, Inteligencia Artificial entre otros.
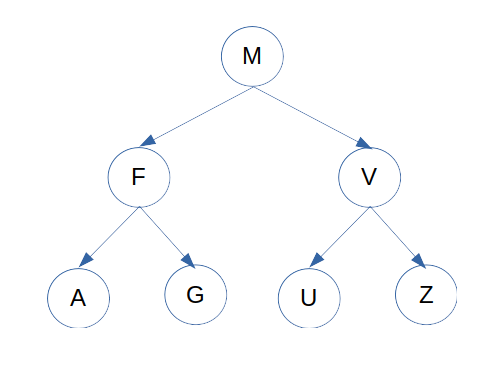 Imagen 8: Árboles
Imagen 8: Árboles
Para su funcionamiento los árboles manejan cierta termilogía que es importante definir:
- Raíz (
root): nodo raíz de toda la estructura. Ejemplo:M - Padre (
parent): nodo del cuál se desprenden nuevas jerarquías. Ejemplo:M,F,V - Hijo (
child): nodo que se encuentra en una jerarquía inferior a otra. Ejemplo:F,V,A,G,U,Z. - Hoja (
leaf): nodo del cuál no se desprende ninguna jerarquía. Ejemplo:A,G,U,Z. - Sibling (
hermano): nodos que se encuentran en un mismo nivel. Ejemplo:F,V,A,G,U,Z.
Existen varios tipos de árboles los cuales tienen un uso específico, entre los comunes tenemos:
- Árboles balanceados: es un tipo de árbol en el cuál sus hojas se encuentran a cierta distancia de su nodo raíz.
- Árboles binarios: es un tipo de árbol en el cuál cada nodo tiene como máximo dos nodos hijos.
- Árboles de búsqueda binaria (BST): en este tipo de árbol se encuentran las siguientes propiedades:
- Los nodos de la rama izquierda contiene únicamente nodos cuyos keys son menores al nodo del cuál se ha partido.
- Los nodos de la rama derecha contiene únicamente nodos cuyos keys son mayores al nodo del cuál se ha partido.
- Cada nodo a su vez es de tipo BST.
- Árboles AVL: es un árbol BST autobalanceado, esto implica que la altura de sus subárboles en cualquier nodo difieren cuando más en uno, en caso contrario es necesario balancear nuevamente el ábol para alcanzar esta propiedad.
- Árboles Red Black: es un tipo de árbol BST autobalanceado con la diferencia que cada nodo del árbol binario tiene un bit extra que representa el color del nodo, este color se usa para asegurar que el árbol permanece balanceado durante los procesos de inserción y eliminación.
- Árboles 2-3: en este caso cada nodo tiene dos hijos (dos nodos) y un elemento de datos o tres hijos (tres nodos) y dos elementos de datos.
- Trie: es un tipo de árbol usado especialmente en la búsqueda y almacenamiento eficiente de cadenas de caracteres, cada nodo almacena los posibles caracteres de un alfabeto.
Implementaciones
Golang
type Tree struct {
Left *Tree
Value int
Right *Tree
}
func traverse(t *Tree) {
if t == nil {
return
}
traverse(t.Left)
fmt.Print(t.Value, " ")
traverse(t.Right)
}
func create(n int) *Tree {
var t *Tree
rand.Seed(time.Now().Unix())
for i:=0; i < 2*n; i++ {
temp := rand.Intn(n * 2)
t = insert(t, temp)
}
return t
}
func insert(t *Tree, v int) *Tree {
if t == nil {
return &Tree{nil, v, nil}
}
if v == t.Value {
return t
}
if v < t.Value {
t.Left = insert(t.Left, v)
return t
}
t.Right = insert(t.Right, v)
return t
}
Java
class Tree {
Tree left;
int value;
Tree right;
}
public void traverse(Tree t) {
if(t == null ){
return;
}
traverse(t.left);
System.out.println(t.Value + " ");
traverse(t.right);
}
public Tree create(int n) {
Tree t = null;
Random rand = new Random();
for(int i=0; i < 2*n; i++) {
int temp = rand.nextInt(n * 2);
t = insert(t, temp);
}
return t;
}
public Tree insert(Tree t, int v) {
if( t == nil ) {
return new Tree(null, v, null);
}
if( v == t.Value ) {
return t;
}
if( v < t.Value ) {
t.Left = insert(t.Left, v);
return t;
}
t.Right = insert(t.Right, v);
return t;
}
Grafos
Un grafo es un conjunto de nodos conectados unos con otros en forma de red, sus nodos son llamados vértices y un par(x,y) es llamado borde (edge) lo cual indica que el vértice x se encuentra conectado con el vértice y. Un borde puede contener peso y costo lo que representa el esfuerzo requerido para atravesar desde un nodo a otro nodo.
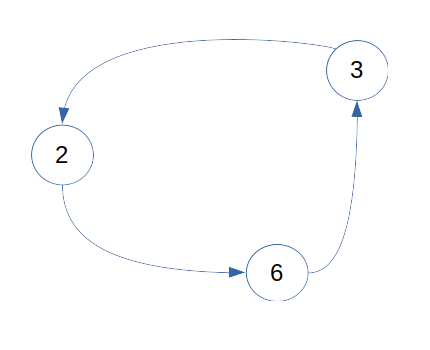 Imagen 9: Grafos
Imagen 9: Grafos
Los grafos pueden ser de tipo:
- Cíclicos: es un grafo donde todos o un número de vértices están conectados formando una cadena.
- Acícliclos: en este caso no existe una cadena cerrada.
- Dirigidos: es un grafo con bordes que tienen una dirección asociada.
- Dirigidos acíclicos: es un grafo dirigido que no tiene ciclos en él.
Archivos
Esta estructura es en realidad una colección de registros que pueden ser obtenidos o almacenados en un dispositivos de almacenamiento secundario, de forma general este tipo de estructura es usada una vez que ha existido un proceso previo generalmente en el cual se involucran otras estructuras de datos, por ejemplo el proceso de matrícula de estudiantes o el pago de las cuotas por la compra en una entidad comercial generalmente resultan en almacenamiento en archivos de la información procesada.
Cada lenguaje ha implementado diferentes formas de procesar archivos, por ejemplo Golang ha definido en el paquete “os” y “io” funciones que permiten abrir, leer y almacenar información, por ejemplo un archivo puede ser abierto mediante la función Open:
file, err := os.Open("file.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close()
b, err := ioutil.ReadAll(file)
fmt.Print(b)
De forma similar en Java se puede tener lo siguiente:
try {
File file = new File("file.txt");
FileInputStream fis = new FileInputStream(file);
System.out.println("file content: ");
int r = 0;
while ((r = fis.read()) != -1) {
System.out.print((char) r);
}
} catch(Exception e) {
e.printStackTrace();
}
Estructuras customizadas
Este tipo de estructuras son creadas por el desarrollador respondiendo a la necesidad que requiera ser modelada e implementada, puede conformarse a su vez de otras estructuras simples y complejas sin existir un límite real en cuanto a la cantidad de elementos permitidos en ellas. Cada elemento de la estructura es denominado campo o atributo dependiendo del tipo de lenguaje usado pero finalmente representa una característica de la entidad modelada, por ejemplo una persona se puede definir mediante sus atributos principales tales como: altura, peso, color de ojos, nombre, género, ciudad de nacimiento, países que ha visitado, etc.
Cada lenguaje ha implementado una forma de manejar este tipo de estructuras, así por ejemplo en el caso de Golang se puede usar el tipo struct para la creación de tipos customizados de datos, por ejemplo:
type empleador struct {
nombre string
id string
}
type persona struct {
altura int
peso int
color_de_ojos string
nombre string
familia map[string]persona
lugar_de_trabajo *empleador
paises_visitados []string
}
Una estructura a su vez se puede componer de otras estructuras lo que permite representar de una forma real la entidad modelada, por ejemplo l atributo persona ha sido definido como un mapa cuya clave es de tipo string y en donde se podría almacenar un id alfanumérico por ejemplo y cuyo valor es una entidad de tipo persona, esto permitiría representar de una forma clara los miembros de una familia. Otro atributo similar es lugar de trabajo que en este caso permite almacenar una entidad de tipo empleador en caso de existir o nil (valor nulo) si no existe.
La representación de estructuras es particular del lenguaje por ejemplo en el caso de Java es necesario el uso de clases (class) para reproducir el mismo efecto:
class Empleador {
String nombre;
String id;
}
class Persona {
int altura;
int peso;
String colorOjos;
String nombre;
Map<String,Persona> familia;
Empleador lugarTrabajo;
List<String> paisesVisitados;
}
Referencias
Las API’s y los ejemplos completos de código se pueden encontrar en los siguientes recursos:
- Mastering Go, Mihalis Tsoukalos
- Golang API
- Java API